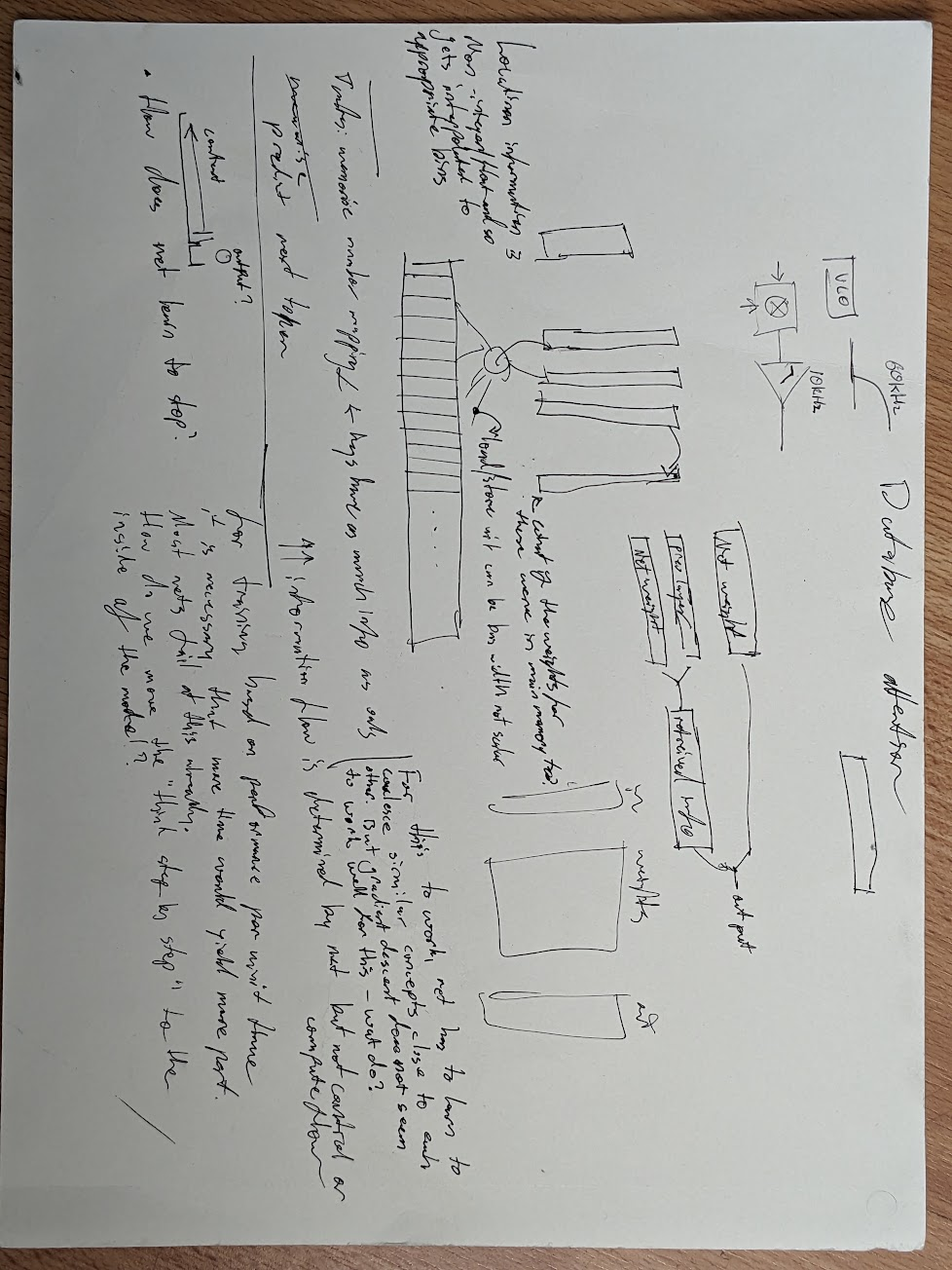
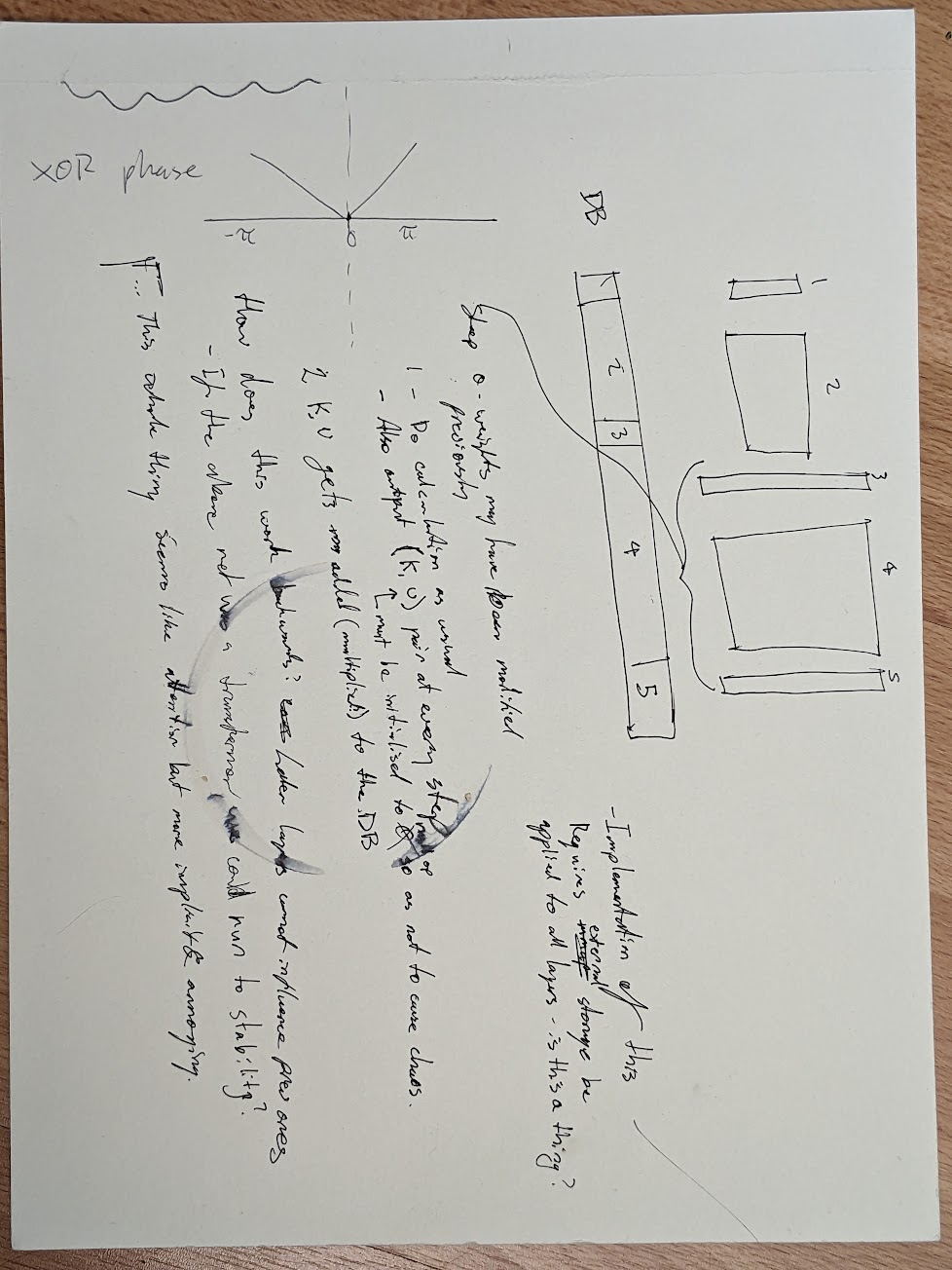
It turns out that this is already a thing of course. Terms of art are :
- Differentiable neural computer - This is distinct from the above in that the DNC seems to have its memory initialised for each problem (i.e. it does not start off as a database of knowledge) and it also seems that the memory controller recurses over it.
- In addition it does the same thing I think from reading the paper where the attention is applied as a multiplication/dot product/whatever across the entire memory space rather than being truly sparse. I think the thing at this point that isn’t obvious is how to make a sparse learned attention to even be differentiable. Other things to look for here are ‘memory augmented transformers’.