It seems that the spidev repository is the one that everyone uses for SPI communication with the jetson. Here is a python script that uses the supposedly fastest spi transaction method, writebytes2:
import numpy as np
import spidev
import time
spi = spidev.SpiDev()
spi.open(3, 0)
spi.max_speed_hz = 50000000 # 50 MHz
spi.mode = 0
while True:
write_data = (np.random.random(3 * 4096 + 100) * 200).astype(np.uint8)
spi.writebytes2(write_data)
# Cleanup
spi.close()
The c code for this is:
static PyObject *
SpiDev_writebytes2_buffer(SpiDevObject *self, Py_buffer *buffer)
{
int status;
Py_ssize_t remain, block_size, block_start, spi_max_block;
spi_max_block = get_xfer3_block_size();
block_start = 0;
remain = buffer->len;
while (block_start < buffer->len) {
block_size = (remain < spi_max_block) ? remain : spi_max_block;
Py_BEGIN_ALLOW_THREADS
status = write(self->fd, buffer->buf + block_start, block_size);
Py_END_ALLOW_THREADS
if (status < 0) {
PyErr_SetFromErrno(PyExc_IOError);
return NULL;
}
if (status != block_size) {
perror("short write");
return NULL;
}
block_start += block_size;
remain -= block_size;
}
Py_INCREF(Py_None);
return Py_None;
}I don’t know much about linux but my understanding is that ‘write’ here is the kernel call.
Here is what the above script looks like on the scope:
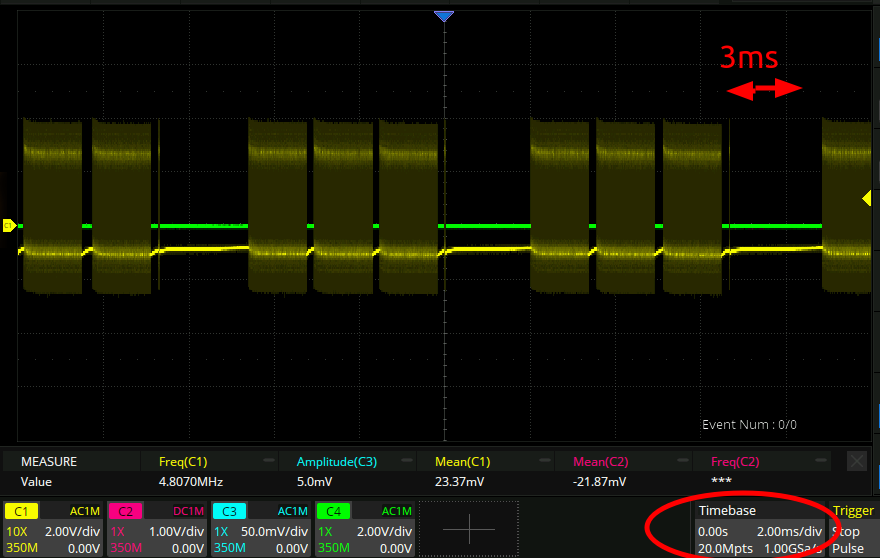
So there are huge gaps between calls to the spi driver, and also quite large gaps between the 4096-long blocks that the driver uses. Unusable for a continuous application!
I guess this means if you want good performance you have to go to the kernel.