The last page was getting a little long so here is a new one.
The main problem with this whole challenge is the super low snr. So far here has what I have done:
- Got an autoencoder (and VAE) to reconstruct the input for both the flattened papyrus with ground truth and the rolled up scroll.
- Failed to train a net directly on the ground truth
- Tried to do a bit of curriculum learning where the net first learned to classify the parts of the scroll where ink was and was not present first. I successfully overfit on those parts of the dataset but that’s about it.
New experiment:
Here’s an idea: add the ground truth ink labels directly into the input of the net! That will make it really easy to train! Indeed it does. Now what I shall do is lower the amount of ink that is added progressively as it trains, like so:
assert(len(batch_vol.shape) == 4)
gt_expanded = batch_gt.reshape((batch_gt.shape[0], 1, batch_gt.shape[1], batch_gt.shape[2]))
gt_expanded = gt_expanded.expand(-1, batch_vol.shape[1], -1, -1)
input_ = gt_expanded * gt_mix_fraction + batch_vol * (1 - gt_mix_fraction)
reconstructed, mu, logvar = model(input_.unsqueeze(1))
...
with torch.no_grad():
loss_scroll = nn.MSELoss()(reconstructed, batch_vol).item()
loss_gt = nn.MSELoss()(reconstructed, gt_expanded).item()
if loss_scroll / loss_gt > 5 and epoch > 100 and gt_mix_fraction > 0:
gt_mix_fraction *= 0.8
This was inspired by how diffusion models are trained to remove noise. If you think of the scroll cube as ‘noise’, then maybe gradually swapping out the input ground truth for the scroll gradually over time is training the model to denoise things and not just a silly idea.
This seems to be working as desired in terms of training:
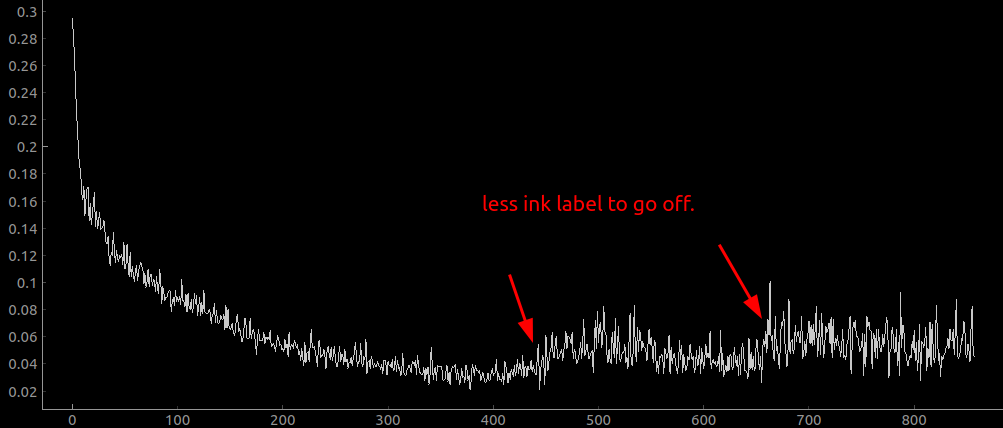
it has gotten down to 0.03 mix fraction after only a few thousand iterations, although the actual output looks like hot garbage:
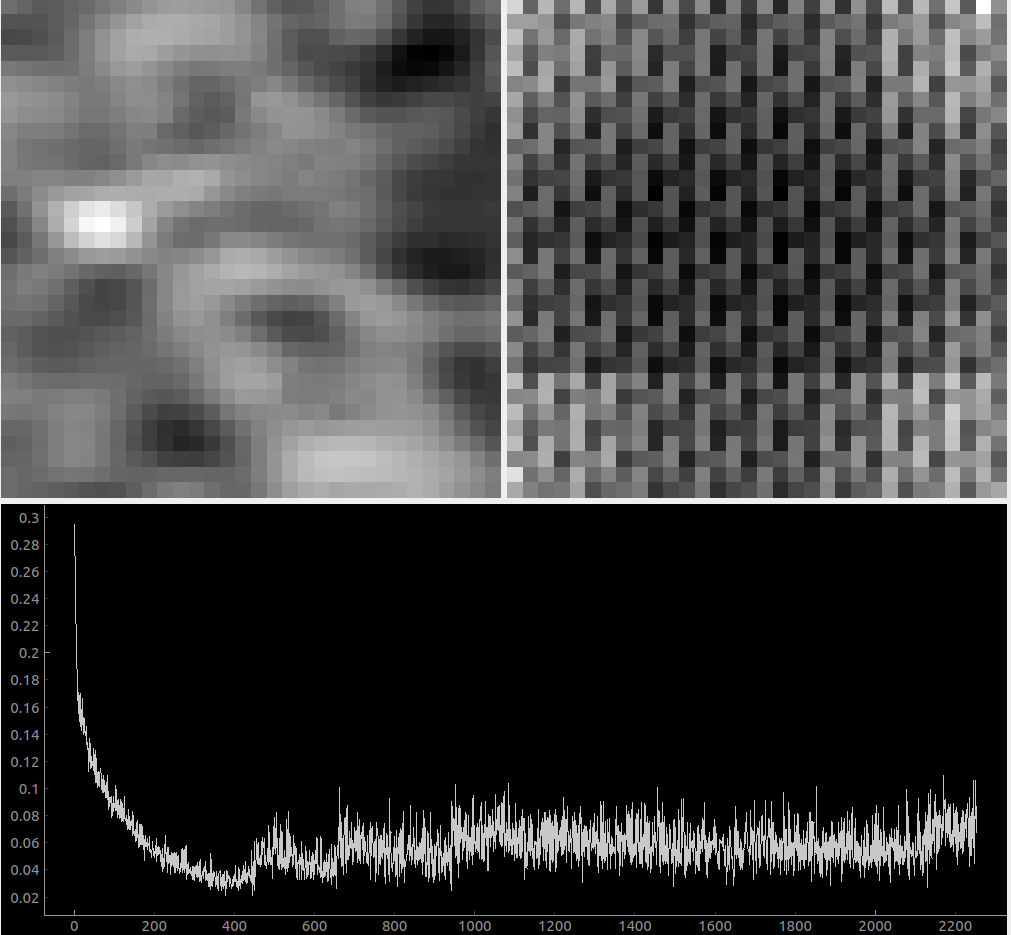
So instead I switched it to decrease the mix fraction every time the loss got below a certain hardcoded number:
This seems even more promising in that the adjustments are much further apart and are having a clear effect, but I don’t know that the improvement on the actual task at hand (extracting ground truth) is any better. If I improved my tool or bothered to learn how the actual pytorch tooling worked I could add additional metrics to track over time, but as-is my spot checks for the loss against the original scroll input are that the curve isn’t really bending much over time.
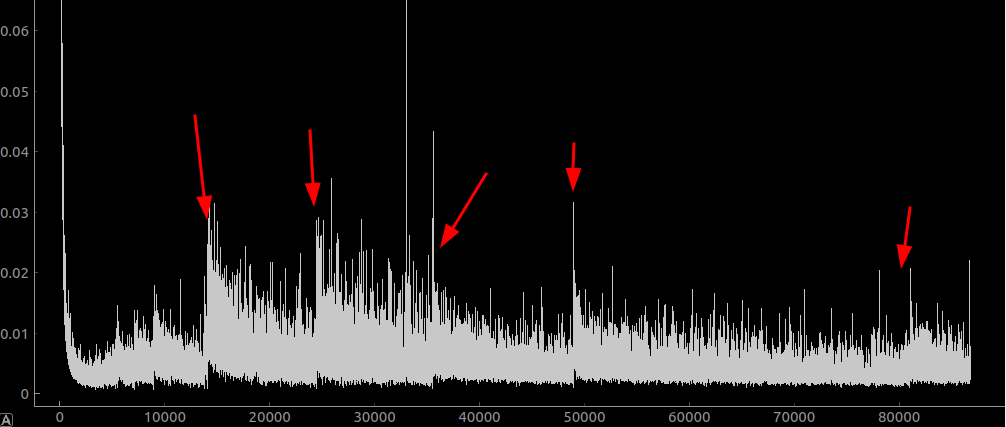
And here is the loss curve after training overnight:
The model is now successfully not using any of the ground truth at all. Super promising!!!
And here are the results of running inference across the whole scroll fragment:

Zoomed in on the region where the training data was derived from:
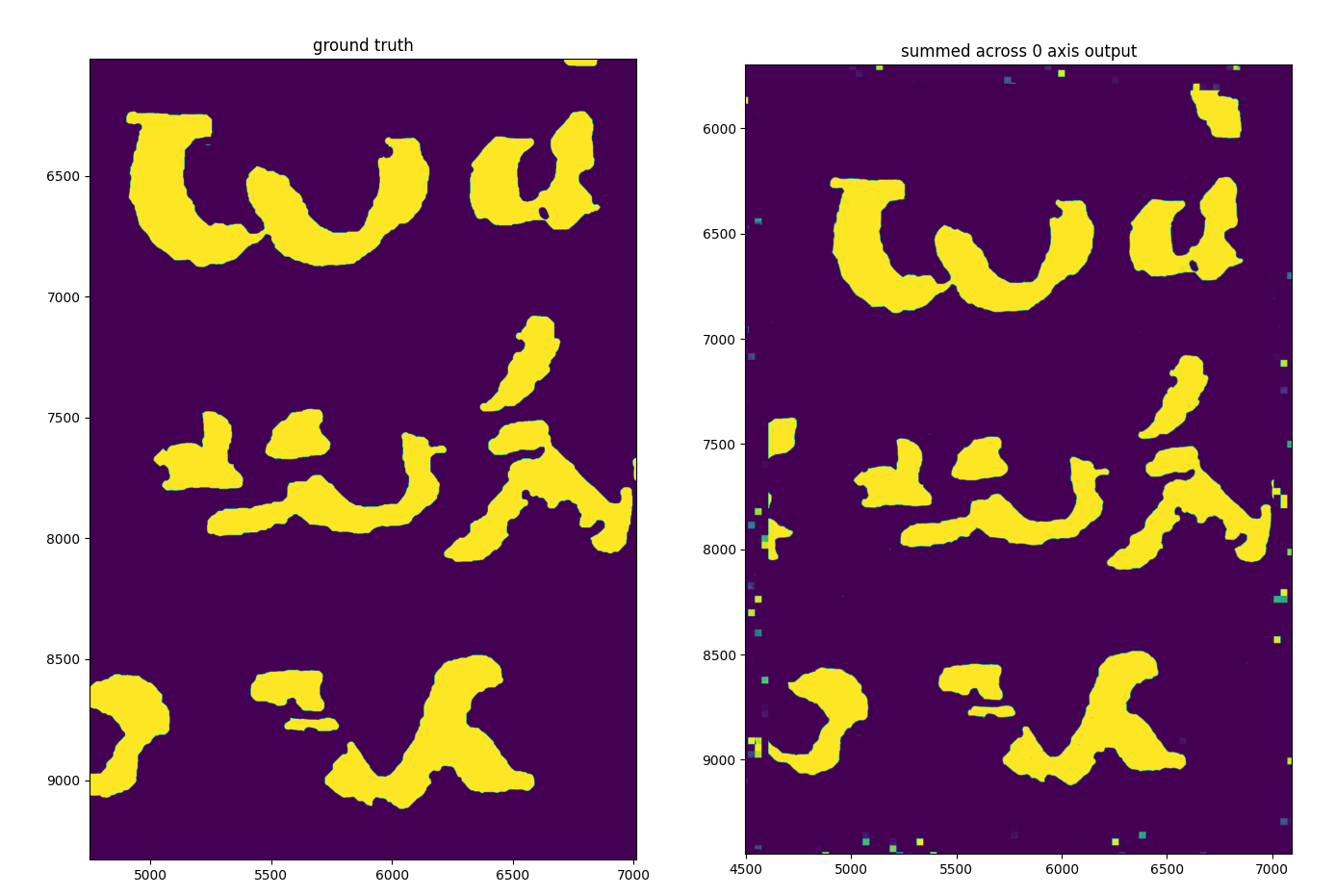
Despite being clearly incredibly overfit to the training data to the point of replicating every last imperfection, this is by far and away the most promising result so far! perhaps by adding a smidge more of the actual scroll as training data + augmenting the inputs a lot the net will actually learn something.
20240115 Augmentation
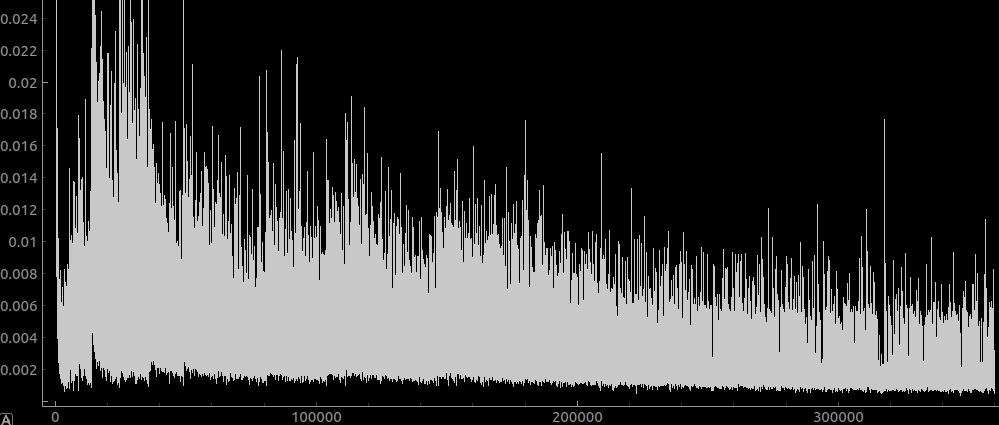
I now trained the network on more or less the same thing, but augmented the dataset with rotations. The training looks like this:
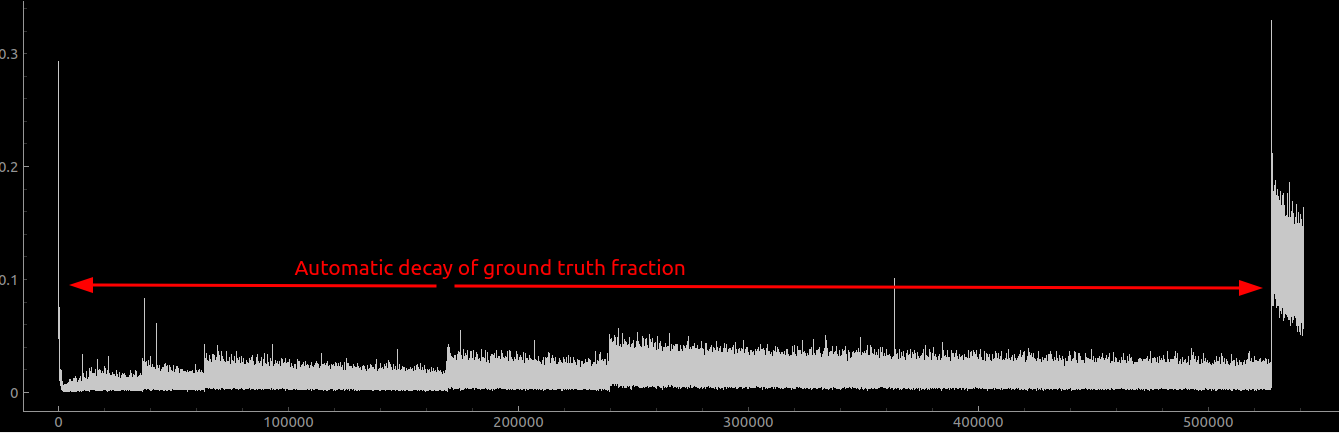
Where I trained it for about 16 hours with the automatically decaying ground truth fraction. The fraction got down to 0.03 whereapon I got bored and manually set it to 0. That resulted in the huge spike in the loss over on the right hand side there, so even at 0.03 the network was still clearly basically only looking at the ground truth.
The conclusion that I draw from this is that when trained without augmentation the training data for the model is small enough that it can be memorised, and when trained with augmentation it can’t generalise to the underlying data.
To be super confident I think I should make some synthetic data with a “scroll” made out of noisy text to see if it can recover the original text.